At The Blue Box we've been running an internal research project to tackle a problem we kept seeing in medical care. The setup we built records consultations, transcribes them, summarizes them in SOAP format, and then analyzes a patient's full visit history longitudinally. The motivation is straightforward: doctors often see different patients every few minutes, and sometimes different doctors see the same patient.
The problem we were trying to understand is a real one, and one that's becoming more common, not less. It's not hard to find people who walk out of a medical appointment feeling like they were treated coldly, processed rather than seen. And it gets worse when you can't count on seeing the same professional twice. Each visit turns into a one-off, and whatever diagnosis or prescription comes out of it rests on a narrow snapshot of who the patient is.
In a world that keeps speeding up, the sheer immediacy of medical consultations ends up working against the patient. The constant turnover depersonalizes them: the doctor who walks in to see the next person often has no real sense of who they are, what they've been through, or what their history looks like. And when that history is exactly what matters - when a good decision depends on seeing the whole arc rather than a single moment - there's rarely enough time to take it into account. That's the gap we were interested in exploring.
The transcription layer is where things got interesting, and complicated.
How Speech Recognition Actually Works
Before getting into the results, it's worth a quick look at what one of these models is doing under the hood, because the way audio gets processed is exactly what makes the failures later on so easy to miss.
At a high level, the pipeline goes through a handful of stages. First, audio capture and preprocessing: the raw sound is converted from an analog signal into a digital one and sliced into small, fixed-length frames so it can be analyzed piece by piece. Whisper, for instance, works with frames of 25 milliseconds, stepping forward 10 milliseconds at a time, and it always processes audio in fixed 30-second windows, padding with silence when a clip is shorter. That fixed window matters: it's how the model keeps enough surrounding context to make sense of any given moment.
Next comes feature extraction. Those frames are turned into a spectrogram, a visual-like representation of how the energy across sound frequencies changes over time. This is the actual input the model sees; it never "hears" the audio the way we do.
Then the encoder takes over. In Whisper this is a Transformer, with a couple of convolutional layers up front, that reads the spectrogram and picks out acoustic patterns: phonemes, the texture of a voice, the shape of speech, while learning to look past background noise.
The decoder is where the text appears. It takes the encoder's representation and predicts the most likely sequence of words, leaning on a language-model-like understanding of context to resolve ambiguity: telling apart homophones, fixing grammar, deciding where a sentence ends. Finally, that output is assembled into a finished transcript, with punctuation and formatting.
The part to hold onto is that everything downstream depends on those early stages. If a low-energy "no" gets buried in a noisy frame, or falls right at the boundary between two chunks, the decoder never gets a clean signal to work with, and the model will still confidently produce a fluent, well-punctuated transcript that simply doesn't contain it. Which is exactly why testing these systems on clean audio can be so misleading.
The Problem With Testing ASR in a Vacuum
Most benchmarks measure word error rate on clean audio. Real medical consultations have background noise, audio dropouts, overlapping speech, and low-energy responses like "mm-hmm" or "no." That last category matters more than it seems, because those short responses are often the clinically relevant ones: a patient confirming a symptom, denying a risk factor, or responding to a direct question about their history.
We tested against a real 10-minute medical audio recording from a public dataset. The file had ambient noise, a couple of dropout moments, and the kind of natural back-and-forth you'd expect in an actual consultation. It was a good proxy for the kind of audio this system would have to handle in the real world.
We tested two models built on very different ideas of how speech recognition should work.
Whisper, from OpenAI, is a general-purpose, multilingual model. It was trained on roughly 680,000 hours of loosely labeled audio scraped from the web, and at that scale it generalizes well to standard benchmarks, often competing with fully supervised systems in a zero-shot setting, with no fine-tuning needed. Architecturally it's a fairly standard encoder-decoder Transformer; OpenAI's bet was on sheer data scale rather than a novel architecture. Importantly for what follows, Whisper isn't a single model. It comes in a range of sizes, from Tiny (39M parameters) through Base, Small, Medium, and Large, plus the newer Turbo (809M), each trading speed for accuracy as you move up. That's the family we walk through below.
MedASR, from Google, takes almost the opposite approach. It's a speech-to-text model based on the Conformer architecture, pre-trained specifically for medical dictation and transcription. Where Whisper is a big generalist, MedASR is small and specialized: a 105-million-parameter model trained on roughly 5,000 hours of de-identified physician dictations spanning specialties like radiology, internal medicine, and family medicine. What sets its training apart is that the audio wasn't just paired with transcripts. It also came with extensive annotations for medical named entities like symptoms, medications, and conditions, which is what gives the model its strong grasp of clinical vocabulary. It takes mono-channel 16 kHz audio and produces text-only transcriptions: no multilingual support, English-only, and explicitly designed to be paired with a generative model like MedGemma for downstream tasks such as SOAP summarization. In other words, it's built to be one stage of a pipeline very similar to ours, which is part of why it was worth testing.
Both were tested on an Apple Mac Mini M4 with 16 GB RAM.
Whisper
On the larger models, Medium and Turbo at least, Whisper handles punctuation, filler words ("uh", "um", "mm-mm"), and conversational flow remarkably well. It even picked up a question that wasn't in the original reference transcript, which we confirmed by listening to the audio ourselves. That fidelity doesn't hold all the way down, though: from Small toward the smaller variants, it starts omitting more and more of those fillers.
But it also silently dropped an entire exchange: "Do you have a family history of cancer?" / "No." Gone. No partial match, no indication anything was missed. We ran the test again and it happened again. In a later run it didn't, which is arguably worse, because it means the failure is inconsistent and hard to anticipate.
For a downstream pipeline that summarizes visit history and looks for patterns across consultations, that kind of silent omission is a real problem. You can't ask a specialist to re-read every transcript after each session.
Processing time on a 10-minute audio file:
- MPS: ~77 seconds
- CPU: ~80 seconds
Those numbers were for Whisper Turbo, the variant we used as our main reference point. That's too slow for a consultation room workflow.
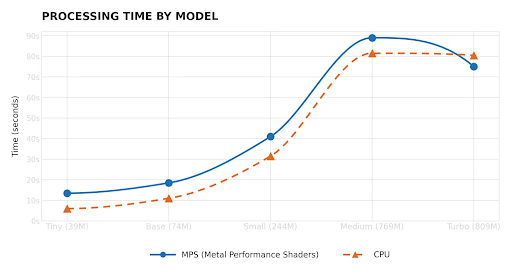
We didn't stop there, though. We ran the same 10-minute audio through the rest of the Whisper family to see how quality and speed shifted across model sizes. We did not test the Large model: given the limited hardware we had on hand, it was taking long enough that we stopped the run before it finished rather than wait it out.
The pattern across the models we did test was consistent. The smaller ones, Tiny and Base, were fast but unreliable. Tiny in particular invented words and mangled whole phrases, which is a non-starter for clinical use. Quality climbed sharply from Small onward, with Medium and Turbo producing transcriptions that were nearly identical to the reference. The interesting part is that Turbo landed in the best spot of the curve: roughly Medium-level quality, but faster. So the tradeoff isn't a clean "bigger is better" line. Past a certain point you're paying a lot of time for very little additional accuracy.
Still, even Turbo's speed is too slow for what we need inside a live session. That said, we're not writing Whisper off. What the results suggest is that we don't necessarily need the biggest model. The smaller variants are already fast, and the real question is whether we can push their quality up. That's where fine-tuning comes in: we're interested in training one of these lighter models on our own medical audio data. The hypothesis is that a smaller, domain-specific model could close the gap on both the reliability and speed problems at the same time. Whether that holds up in practice is something we'll need to test, but it feels like a more promising path than trying to make the larger general-purpose models work in a clinical context out of the box.
MedASR
MedASR is a small, efficient model from Google, specifically designed for medical speech. The speed difference was dramatic: 2.1 seconds on MPS for the same audio that took Whisper over a minute. That's the kind of latency you could actually run inside a session.
The quality, though, didn't come close to Whisper. In our initial setup we applied chunking in 10-second blocks with no stride overlap, which created context gaps at the segment boundaries. The model dropped patient responses consistently, especially the short ones, and surfaced raw tokens like {end} and [unintelligible] straight into the output, which is the last thing you want in a medical transcript. Switching to Hugging Face's pipeline with configurable chunk and stride sizes helped noticeably: more complete exchanges, more responses captured. But even at its best it stayed well behind what Whisper was producing out of the box.
We didn't push MedASR much further than that, though. Our testing was focused on Whisper, and MedASR served a different purpose here: it was a window into a different architectural approach to the same problem. Seeing how a small, purpose-built medical model behaves, where it breaks, what it's fast at, and what it sacrifices, helped us reason about why Whisper is as slow as it is, and why its transcriptions hold up the way they do. We still think MedASR has real headroom: with fine-tuning and a better chunking strategy, its quality could improve a lot. It just wasn't the focus this time around.
What This Actually Means for Healthcare ASR
The framing of "which model is better" turned out to be the wrong question. The right question is: what kinds of errors can you tolerate?
In most ASR applications, a missed word or a short dropped response is a minor annoyance. In a medical context, it can mean a missing risk factor, a skipped symptom, or an incorrect downstream summary. The error doesn't announce itself. It just quietly shapes everything that comes after it.
None of this is especially exotic. The pieces exist. The challenge is combining them in a way that's reliable enough to actually deploy in a clinical setting, where the cost of a silent error isn't just a worse user experience, but potentially a worse outcome for a patient.
Conclusion
If there's one thing this process made clear, it's that the hard part of medical ASR isn't picking a model. It's deciding which errors you're willing to live with. A fast transcription that quietly drops a patient's "no" is worse than a slow one that gets it right, because the failure doesn't announce itself. It just propagates into the summary, the history, and eventually the decisions made on top of them. Speed only matters once reliability is in place.
So the path forward, for us, isn't chasing the biggest or newest model. It's narrowing in on a smaller, domain-specific one we can fine-tune on real medical audio, ideally in Spanish, our primary use case, and small enough to run locally on a phone, without sending a single second of patient audio to the cloud.
References
- Making automatic speech recognition work on large files with Wav2Vec2 in Transformers Link
- What Is Speech Recognition? IBM Link
- Conformer: Convolution-augmented Transformer for Speech Recognition Link
- Whisper: Robust Speech Recognition via Large-Scale Weak Supervision Link
- Whisper Long-Form Transcription Link
- Understanding Whisper's Encoder-Decoder Transformer Architecture Link
- Whisper: Functionality and Finetuning Link

Written byFacundo Ferrari
Small team. Smart systems. Real impact.
Newsletter Signup