
A Technical Overview: Prompt Engineering, Web Search Models, and Clean Data Pipelines
Building a reliable information retrieval system for U.S. non-profit organizations (NPOs), espefically for churches, is challenging. Public data is fragmented, inconsistent, and often incomplete. For platforms that rely on accurate institutional details like: board members, pastors, emails, addresses—precision is non negotiable.
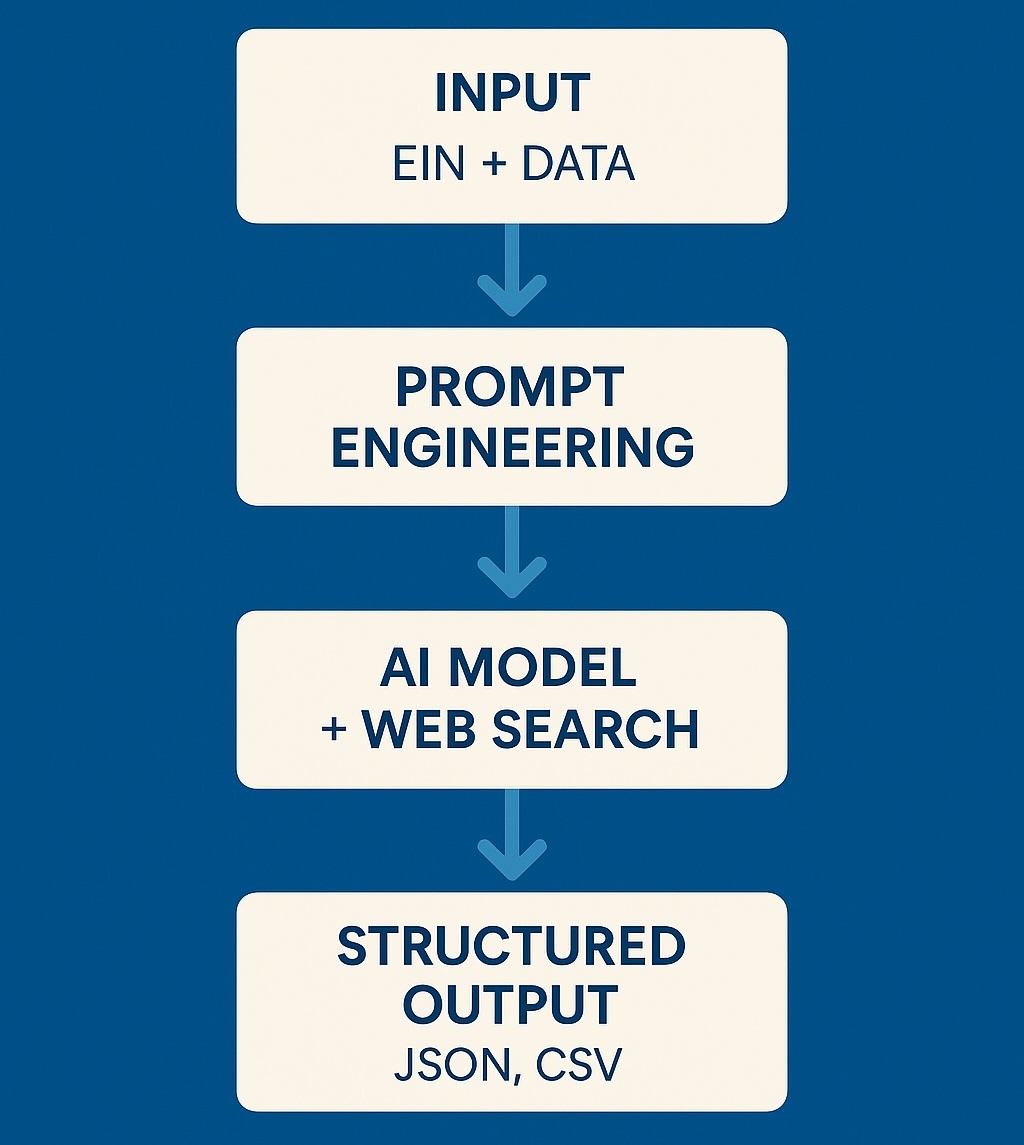
At The Blue Box, we designed an AI-driven pipeline capable of retrieving only verified public information, rejecting hallucinated content, and delivering clean, structured output.
The Problem: Why NPO Data Is Hard
NPO information varies widely across sources. IRS registries may list only the legal name and address. Churches often do not list staff online. Emails or board members are frequently missing. This leads to three systemic challenges:
+----------------------+------------------------------+
| Challenge | Impact |
+----------------------+------------------------------+
| Missing information | Must NOT be hallucinated |
| Fragmented sources | Requires cross-verification |
| Heterogeneous data | Hard to structure uniformly |
+----------------------+------------------------------+
Given this context, we should design a safe AI pipeline that enforces strict adherence to verifiable public sources, ensuring that every data point is validated exclusively through official channels such as IRS records, government registries, and the organization’s own website.
The system operates with zero tolerance for hallucinations or inferred information, prioritizing accuracy over completeness by returning “Unknown” whenever a field cannot be publicly confirmed.
To maintain reliability across the entire workflow, the pipeline consistently generates deterministic, machine-readable output, enabling downstream systems to process and integrate the data without ambiguity.
At the same time, it must remain cost-efficient and scalable, carefully balancing model selection and output formats to support high-volume processing while avoiding unnecessary computational overhead.
Prompt Engineering Strategy
Our prompts evolved into a strict rule-based specification designed to minimize ambiguity and eliminate hallucinations. We established explicit source requirements, instructing the system to rely solely on publicly verifiable information from official or authoritative channels.
We also incorporated deep EIN verification, requiring the system to match each organization using validated IRS identifiers before retrieving any additional information.
Finally, we introduced a deliberate penalty for unverified or ambiguous data, any field that cannot be confirmed must return exactly “Unknown”, reinforcing conservative behavior and preventing the model from guessing or completing fields without evidence.
Output Formats
During the design process, we evaluated three different output formats: JSON, CSV, and our internal TOON structure to determine which one offered the best balance between accuracy, ease of parsing, and operational cost.
JSON provided the richest structure and was ideal for API integrations, but its verbosity increased token usage, making it more expensive for large scale batch processing.
CSV worked well for bulk datasets and spreadsheet workflows, but lacked hierarchical structure, which introduced ambiguity when representing lists such as board members or pastors.
TOON, our custom lightweight extraction format, offered a middle ground: it maintained structure while keeping outputs compact and predictable.
After benchmarking the cost and performance of each option in high-volume scenarios, we ultimately selected TOON as the primary output format. Its compactness significantly reduced token consumption, enabling us to scale the system efficiently without compromising on data quality or reliability.
Key Results
The system achieves high factual accuracy while consistently delivering structured, machine-readable outputs that downstream services can rely on. Its strict zero-hallucination policy ensures that no information is inferred or fabricated, reinforcing trust in every result.
In addition, the pipeline supports fast batch processing, enabling efficient handling of large volumes of nonprofit records.
Together, these capabilities create a reliable verification workflow that remains stable, predictable, and scalable across diverse datasets and real-world conditions.
Lessons Learned
Throughout this project, we learned that strict, constraint driven prompts consistently outperform more flexible or open ended approaches, especially when accuracy is critical.
We also confirmed that small, efficient models paired with targeted web search often deliver better factual results than larger models operating without external verification.
Deterministic output schemas proved essential for preventing downstream errors, ensuring that every component in the pipeline receives predictable and structured data. Just as importantly, we recognized that returning “Unknown” when information cannot be verified is fundamental to maintaining data integrity and avoiding hallucinations.
Finally, the entire process reinforced the importance of continuous iteration and testing, as each refinement, whether in prompts, schemas, or model configuration, meaningfully improved the system’s reliability and performance.
Conclusion
Accurate nonprofit information is critical for trust, compliance, and platform integrity. By combining careful prompt engineering, robust model selection, structured output schemas, and a disciplined “no-assumptions” approach, we built a reliable AI system capable of retrieving verified nonprofit data at scale. The result is a pipeline that organizations and users can trust.
Do you have questions about how implement AI in your process?
Written byThe Blue Box
Small team. Smart systems. Real impact.
Newsletter Signup