
Legal AI Platform – ipsaIQ Case
At The Blue Box, we worked alongside ipsaIQ on the evolution of a legacy AI platform built to process and search legal case information through semantic technologies.
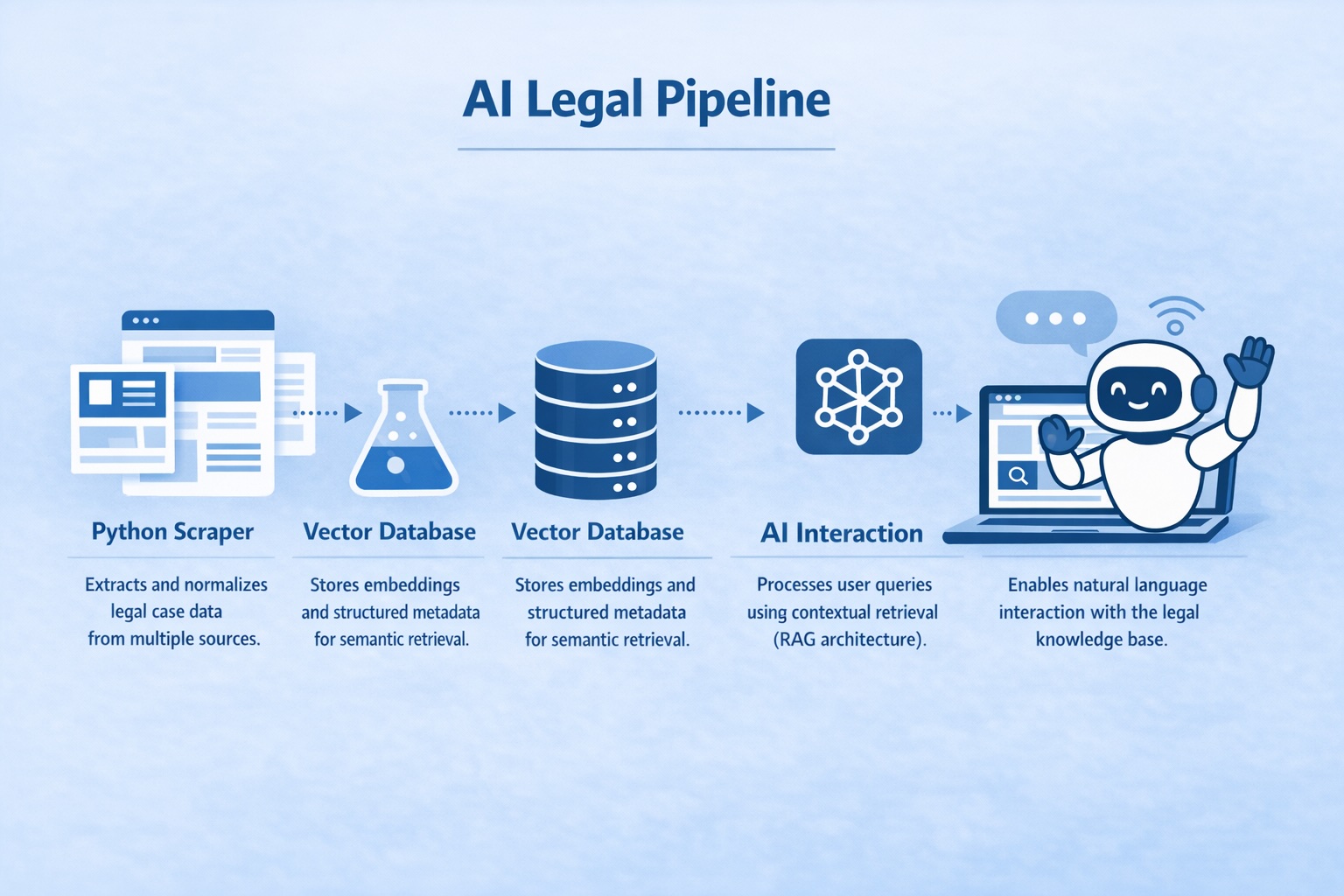
The system was already operational. It included a public web interface, a CMS, an AI-powered scraping pipeline, embedding generation, and semantic search capabilities. This was not a greenfield AI build. It was our first Legacy AI optimization project, where the real value was not in creating new features, but in improving architecture, efficiency, and scalability.
Understanding the Real Challenge
Many AI platforms reach a functional state and stop there. They work. They retrieve. They generate answers. But under the surface, architectural inefficiencies accumulate — excessive token usage, poorly designed chunking strategies, redundant embeddings, and vector databases that grow without governance.
ipsaIQ already had semantic search in place. Our role was to analyze the entire pipeline end-to-end and identify where meaningful improvements could be applied without disrupting the existing product experience.
We focused on strengthening what was already working.
Refining the Scraping and Data Preparation Layer
The platform relied on a Python-based scraping pipeline that collected legal case information from multiple sources. Instead of increasing volume, we concentrated on improving data quality and structure.
We refined normalization processes, standardized legal metadata such as jurisdiction, dates, parties involved, and case types, and reduced duplication before embeddings were generated. In AI systems, the quality of preprocessing directly affects retrieval accuracy. Better structured data produces better semantic representations.
More data does not necessarily mean better results. Cleaner context does.
Rethinking the Vector Strategy with Weaviate
The vector database was already in place. However, vector databases are not passive storage layers — they are architectural components that require strategy.
We redesigned the chunking logic to be semantically coherent rather than arbitrarily size-based. We ensured that structured metadata remained separate from embedded content to allow hybrid queries combining filters and vector similarity. We also prepared the architecture for incremental re-indexing instead of full reprocessing cycles.
One of the most common inefficiencies in legacy AI systems is embedding everything without a retrieval strategy. That approach increases costs and reduces precision over time. Optimizing what gets embedded — and how — significantly improves both performance and sustainability.
Token Consumption as an Architectural Decision
Token optimization was one of the key areas of improvement. Many AI systems send excessive context to the model because it feels safer to overprovide information. But that directly impacts cost, latency, and scalability.
We implemented smarter context selection, reduced redundancy in prompt construction, and improved retrieval precision so that the model receives only what it truly needs. Token consumption is not a minor technical detail. It is a structural business decision that affects long-term viability.
Modernizing Without Breaking
One of the most valuable lessons from this project was that modernization does not require replacement.
We did not rebuild ipsaIQ’s platform. We reinforced it.
Legacy AI systems represent a significant opportunity. Many companies already have AI integrated into their products. Few have optimized it at the architectural level. The real competitive advantage often lies not in adopting AI, but in refining it.
This project confirmed something we increasingly observe: AI maturity is not defined by having embeddings or a chatbot interface. It is defined by how efficiently, sustainably, and intelligently the entire pipeline operates.
Curious how improve your AI pipeline?
Written byThe Blue Box
Small team. Smart systems. Real impact.
Newsletter Signup